Google Location History
When enabled, Google Maps can keep a log of your location history. This can be a rich source of data for your timeline.
Before 2025, location history was exported via Google Takeout. In December 2023, Google announced it would delete your location history from its servers, which happened by 2025. Now, it is only stored on your device and is auto-deleted after some time unless you opt into keeping it.
How to get it
-
Open the Settings app.
-
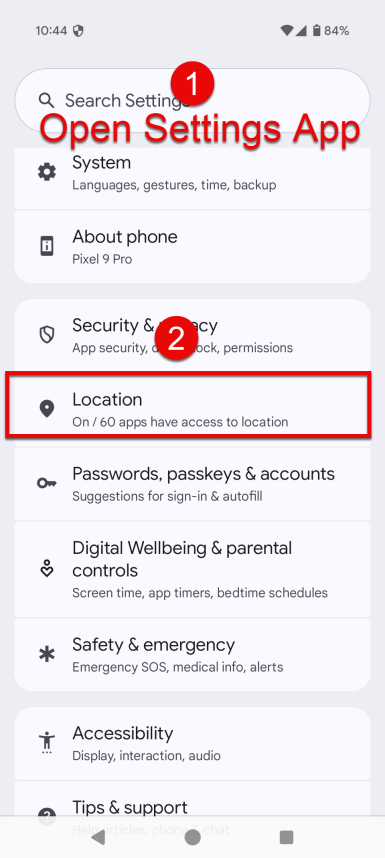
Tap Location.
-
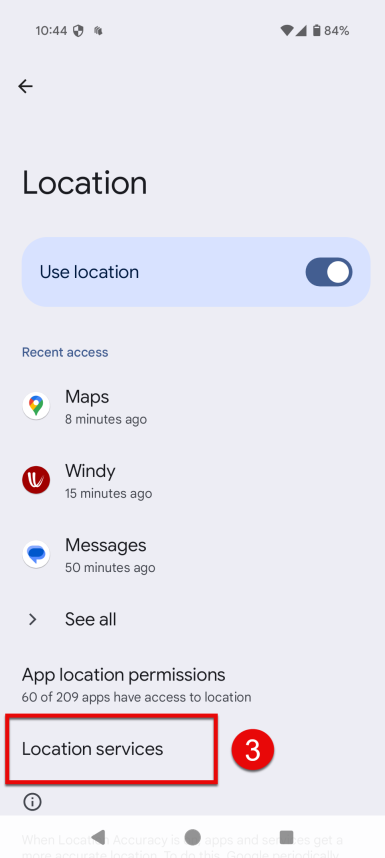
Tap Location services.
-
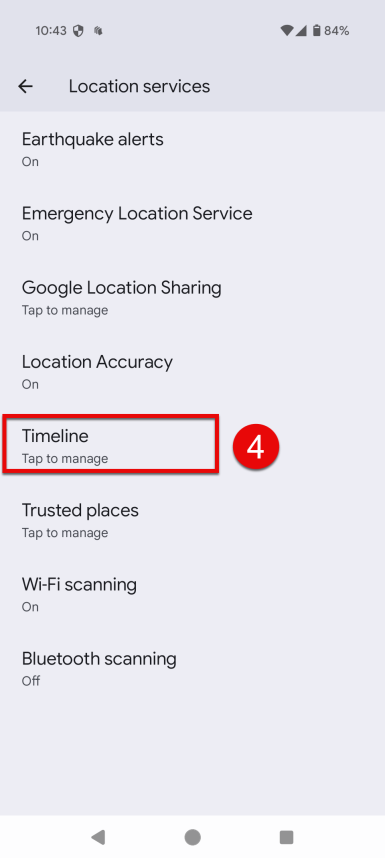
Tap Timeline.
-
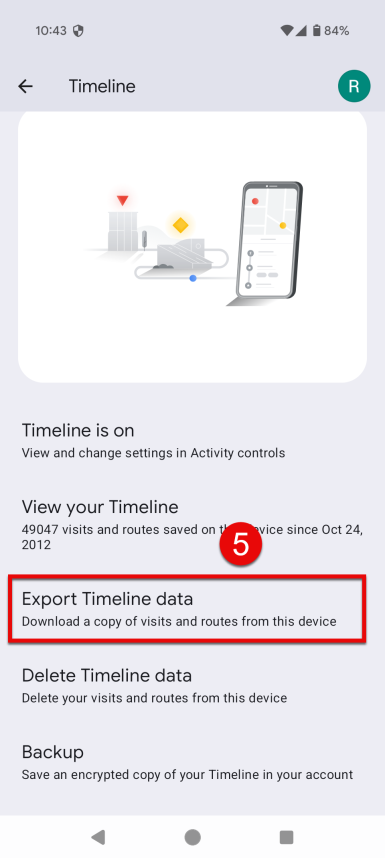
Tap Export timeline data.
Expected format
Timelinize supports both the legacy location history format (from Takeout, pre-2025), and the current on-device export format. It should remain its original archive file, or it may be extracted as long as its folder structure is preserved.
For on-device exports, the filename matters so that the import planner doesn't have to open and parse every JSON file it encounters. Leave the filename unchanged; or, you can add to it, but don't remove anything from the original name. For example, if your filename was Timeline.json, you can change it to Timeline 2024-09-15.json, but don't change the extension or remove "Timeline".
Filenames may vary by locale/language; not all languages are supported yet, but many common ones are. Please file an issue if your file is not recognized by the import planner, and we will add your language.
Options
Owner
Select the entity whom the location data represents.
Simplification
A value from 1-10 that indicates how aggressive to be at simplifying paths formed by data points in chronological order. A higher value can save space and speed up imports, but will preserve less detail related to your movements. A lower value preserves more movement data, but can take longer to import and use more space. (Space should not be a huge concern, we are talking KB or a few MB at most.)
To visualize the effect this setting has, try one of these playgrounds for the Ramer-Douglas-Peucker algorithm:
We usually recommend leaving this at or near the default value unless you have a reason to change it.
Device
Location data stored on-device has no information to manifest which device it came from, so enter something descriptive here (e.g. "Pixel 7 Pro" or "My 2022 iPhone").
What is imported
The legacy Takeout archive has raw location records and semantic history. Currently, we process only the raw location data, but it is planned to incorporate the highly detailed (but often incorrect) semantic history due to its rich place data, route snapping, and feature inference.
The on-device location history is a watered down form of its predecessor, but we still get coordinates, timestamps, and some basic metadata.
Processing
The raw location history is complex and noisy. Our import process first de-duplicates, then de-noises, then simplifies the points to make them more legible and to reduce the size of the data set without losing significant detail. The level of simplification can be customized.
The legacy archive interleaves data from multiple devices, meaning we have to scan through the data once per device. This ensures that our de-duplication, de-noising, and path simplification algorithms work on a single physical device's path instead of mixing different paths, which introduces errors into the statistical analysis and produces incoherent results. To speed this up, each device's data points are read in parallel. In other words, we keep your CPU as busy as possible during the import.
As devices usually do not appear throughout the entire data set, progress may appear to stall at times. It's normal if it looks like the job for this data source is idle for a few seconds or minutes.